用彩虹社YouTube直播聊天訊息來練習Elasticsearch
前言
以前因為工作需要而接觸到ELK Stack,對kibana的介面很有興趣,但因為Elasticsearch對記憶體的要求相對地比較高,所以一直都沒有在工作以外的地方使用到。直到最近終於組了一台桌機,可以把Deskmini a300空出來後,就能跑Hyper-V服務來開個機器來練習了。
安裝
首先就按照官方的指示把Elasticsearch和kibana安裝起來,接著開啟各自的設定檔將IP從localhost改成內網IP:
https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
https://www.elastic.co/guide/en/kibana/current/install.html
# 在/etc/elasticsearch/elasticsearch.yml中將network.host的值修改為內網IP
network.host: 1.2.3.4
# 在/etc/kibana/kibana.yml中將server.host與elasticsearch.hosts的值修改為內網IP
server.host: "1.2.3.4"
elasticsearch.hosts: ["http://1.2.3.4:9200"]
畢竟機器只有一台,所以就都安裝在一起了。
順利的話,用瀏覽器開啟或是curl網址http://1.2.3.4:9200就可以看到一個JSON字串:
{
"name" : "localhost.localdomain",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "17ltgljUSjjJBhq9UpqwlQ",
"version" : {
"number" : "7.10.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "51e9d6f22758d0374tyf3f5c6e8f3a7997850f96",
"build_date" : "2020-11-09T21:30:33.964949Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
用瀏覽器開啟http://1.2.3.4:5601則是能看到kibana首頁。
加入資料
去年開始就有在持續在取得にじさんじ在YouTube直播的聊天訊息,一支影片一個檔案,檔案裡每行為一個JSON字串,用斷行符號分隔。
儲存位置大致上是:
https://n7i-fans.pickoma.com/chats/YYYYMM/VIDE_ID.ndjson
內容像是這樣:
{"channel_id":"UCoztvTULBYd3WmStqYeoHcA","video_id":"nH8EKvZWixY","chat_id":"Cg0KC25IOEVLdlpXaXhZKicKGFVDb3p0dlRVTEJZZDNXbVN0cVllb0hjQRILbkg4RUt2WldpeFk","user_id":"UCoztvTULBYd3WmStqYeoHcA","user_name":"笹木咲 / Sasaki Saku","is_verified":true,"is_owner":true,"is_sponsor":false,"is_moderator":false,"message_id":"LCC.CjgKDQoLbkg4RUt2WldpeFkqJwoYVUNvenR2VFVMQllkM1dtU3RxWWVvSGNBEgtuSDhFS3ZaV2l4WRI5ChpDTy1oazdYejJlc0NGWUZVN1FvZGNaZ0ctZxIbQ05mTHZ2M3QyZXNDRmJPWXdnb2RTMXdMYVEw","post_time":"2020-09-08T15:44:41.787000Z","content":"音量大丈夫???","amount":"¥0","amount_micros":0,"currency":"none","play_time":"00:11:00","view_count":"9680","live_view_count":"8247","like_count":"984","dislike_count":"6","fav_count":"0","comment_count":"0","is_new_sponsor":false}
所以準備了兩個Bash Script把它們灌進Elasticsearch:
fetch.sh
T_PWD="/usr/n7i"
T_YYYY=$1
T_MM=$2
T_DD=$3
if [ "$T_YYYY" == "" ]; then
echo "year input failed."
exit 1
fi
if [ "$T_MM" == "" ]; then
echo "month input failed."
exit 2
fi
if [ "$T_DD" == "" ]; then
echo "date input failed."
exit 3
fi
T_URL_RECORDS="https://n7i-fans.pickoma.com/stats/records-$T_YYYY$T_MM.ndjson"
T_LIST=$( curl -s "$T_URL_RECORDS" )
T_TARGET_PATH="$T_PWD/$T_YYYY/$T_MM"
mkdir -p "$T_TARGET_PATH"
mkdir -p "$T_TARGET_PATH/queue/"
mkdir -p "$T_TARGET_PATH/done/"
T_LIST=$( echo "$T_LIST" | sed -e 's/\\"/"/g' )
while read T_ITEM; do
T_VIDEO_ID=$( echo -n "$T_ITEM" | jq -r .id )
if [ ! -f "$T_TARGET_PATH/done/$T_VIDEO_ID" ]; then
curl -s "https://n7i-fans.pickoma.com/chats/$T_YYYY$T_MM/$T_VIDEO_ID.ndjson" > "$T_TARGET_PATH/queue/$T_VIDEO_ID.ndjson"
T_LINE_COUNT=$( cat "$T_TARGET_PATH/queue/$T_VIDEO_ID.ndjson" | wc -l )
if (( $T_LINE_COUNT > 1000 )); then
split -l 1000 -d "$T_TARGET_PATH/queue/$T_VIDEO_ID.ndjson" "$T_TARGET_PATH/queue/sp_$T_VIDEO_ID.ndjson."
for T_FILE in `ls $T_TARGET_PATH/queue/sp_$T_VIDEO_ID.ndjson.*`; do
sh "$T_PWD/do-bulk.sh" "$T_FILE"
rm "$T_FILE"
done
else
if (( $T_LINE_COUNT <= 0 )); then
echo "$T_LINE_COUNT <= 0"
else
sh "$T_PWD/do-bulk.sh" "$T_TARGET_PATH/queue/$T_VIDEO_ID.ndjson"
fi
fi
touch "$T_TARGET_PATH/done/$T_VIDEO_ID"
rm "$T_TARGET_PATH/queue/$T_VIDEO_ID.ndjson"
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $T_VIDEO_ID done."
else
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $T_VIDEO_ID is already done."
fi
done <<< $T_LIST
do-insert.sh
#!/bin/sh
T_FILE=$( echo "$1" | awk -F '/queue/' '{print $2}' )
T_URL_BULK="http://10.0.0.19:9200/_bulk"
T_DATA_BULK=""
T_PATH_BINARY="/usr/n7i/binary/$T_FILE"
while read -r T_LINE; do
if jq -e . > /dev/null 2>&1 <<< "$T_LINE"; then
T_ID=$( echo -n $T_LINE | jq -r .message_id )
T_POST_TIME=$( echo -n $T_LINE | jq -r .post_time )
T_YYYY=$( TZ=Asia/Taipei date -d "$T_POST_TIME" +%Y )
T_MM=$( TZ=Asia/Taipei date -d "$T_POST_TIME" +%m )
T_DATA=$( echo -n $T_LINE | jq -c '{ amount_micros: .amount_micros , channel_id: .channel_id , content: .content , currency: .currency , is_moderator: .is_moderator , is_new_sponsor: .is_new_sponsor , is_owner: .is_owner , is_sponsor: .is_sponsor , is_verified: .is_verified , play_time: .play_time , post_time: .post_time , user_id: .user_id , user_name: .user_name , video_id: .video_id }' )
T_DATA_BULK="$T_DATA_BULK{\"index\":{\"_index\":\"n7i-chats-$T_YYYY$T_MM\",\"_id\":\"$T_ID\"}}\n$T_DATA\n"
else
echo "parse json failed. $T_LINE"
fi
done < "$1"
echo -e $T_DATA_BULK > "$T_PATH_BINARY"
curl -s -H "Content-Type: application/x-ndjson" -X POST "$T_URL_BULK" --data-binary "@$T_PATH_BINARY" >> /dev/null
rm "$T_PATH_BINARY"
fetch.sh會去取得影片清單後,依序下載各個影片的聊天訊息資料,接著在交給do-insert.sh處理。
等資料都進去後,就可以開啟kibana的discover頁面來看看。
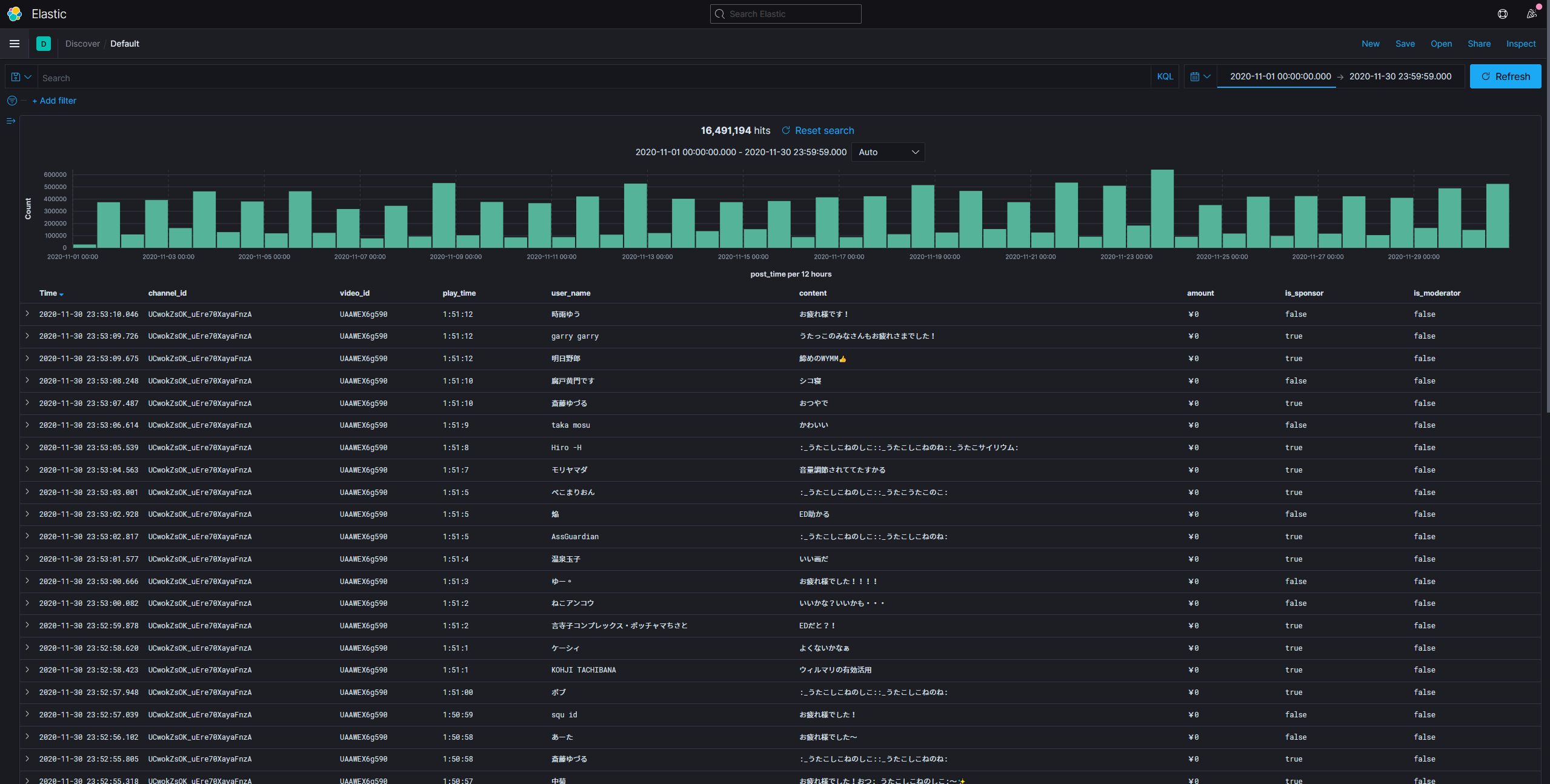
新版的kibana直接有dark mode可以使用,看起來整個就舒服多了。
基本查詢
資料都進去後,就可以到Kibana裡的Dev Tools頁面測試:
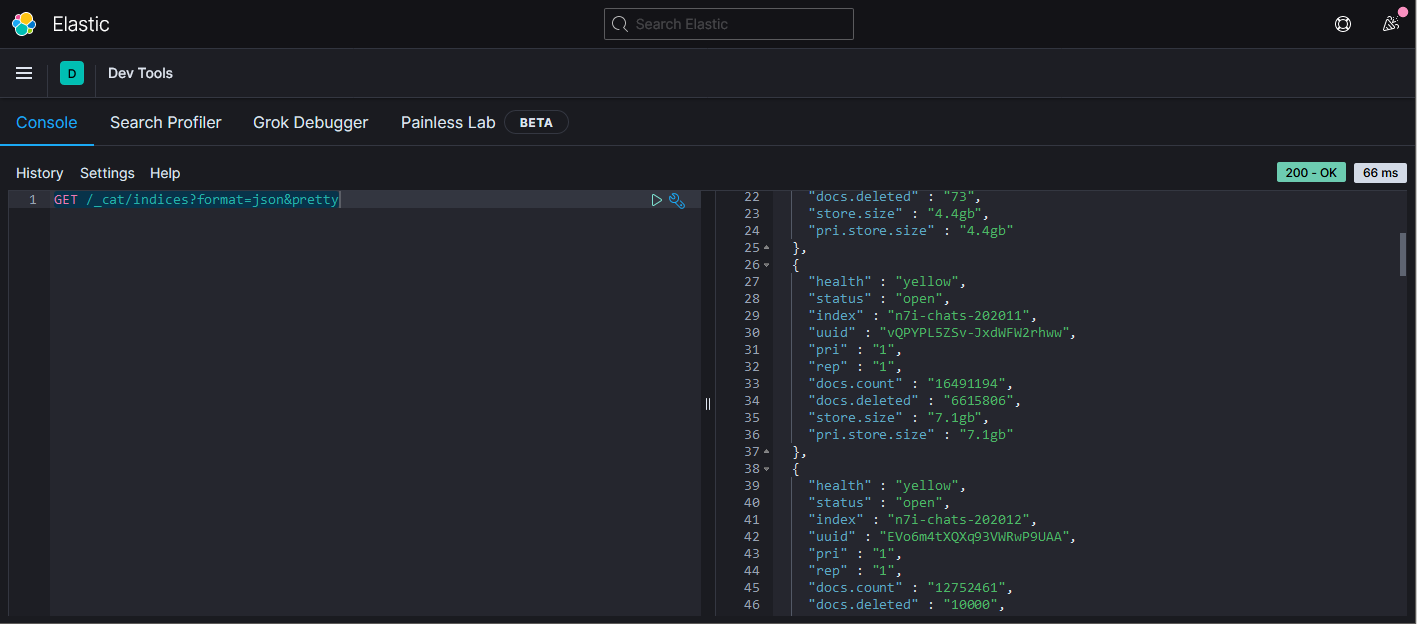
GET /_cat/indices?format=json&pretty
使用GET方法呼叫/_cat/indices列出目前所有資料表(索引)的資料筆數與檔案大小。
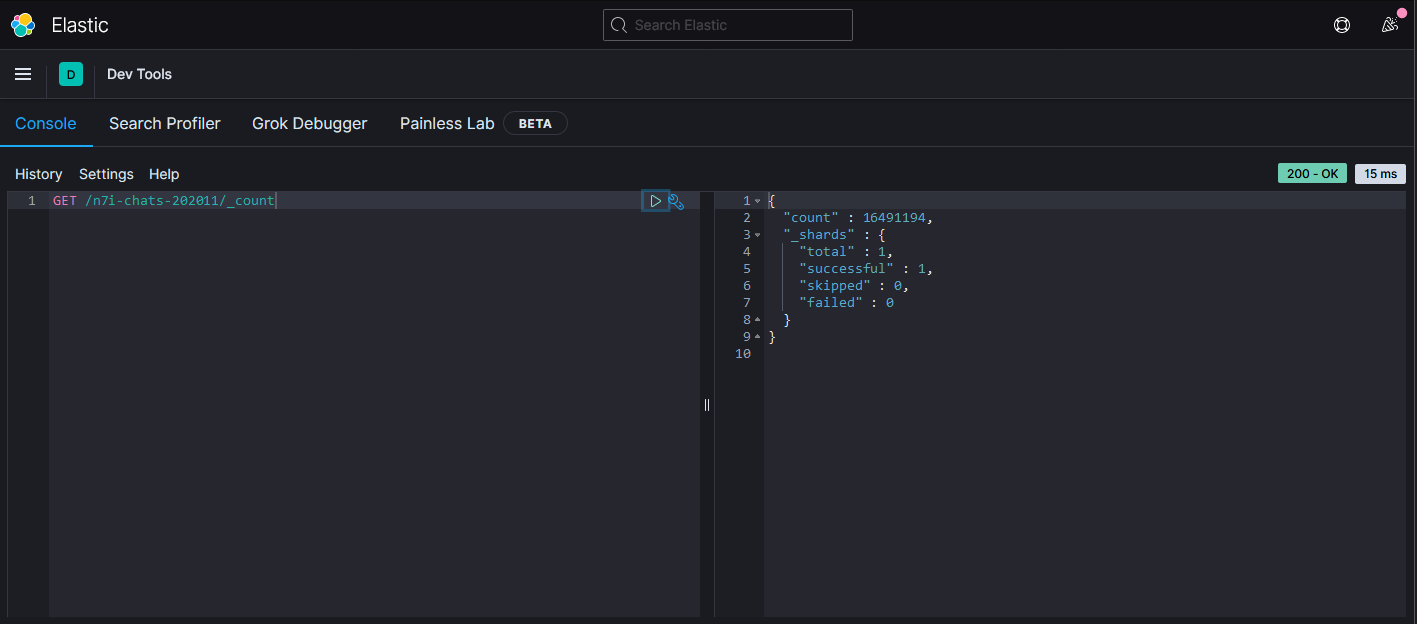
GET /n7i-chats-202011/_count
使用GET方法呼叫/索引名稱/_count就可以得到該索引有多少筆資料。
GET /n7i-chats-202011/_count?q=channel_id:UCoztvTULBYd3WmStqYeoHcA
可以使用q參數放入簡單的查詢條件。

GET /n7i-chats-202011/_count
{
"query":{
"bool": {
"must": [
{
"term": {
"channel_id.keyword": {
"value": "UCoztvTULBYd3WmStqYeoHcA"
}
}
}
]
}
}
}
如果是比較複雜的條件,就可以寫在data裡面。
GET /n7i-chats-202011/_search
{
"query":{
"bool": {
"must": [
{
"term": {
"channel_id.keyword": {
"value": "UCoztvTULBYd3WmStqYeoHcA"
}
}
}
]
}
}
}
把_count換成_search就會變成查詢資料。
GET /n7i-chats-202011/_search
{
"query":{
"bool": {
"must": [
{
"term": {
"channel_id.keyword": {
"value": "UCoztvTULBYd3WmStqYeoHcA"
}
}
}
]
}
},
"sort": [
{
"amount_micros": {
"order": "desc"
}
}
]
}
可以使用sort屬性來對資料排序。
GET /n7i-chats-202010,n7i-chats-202011/_search
{
"query":{
"bool": {
"must": [
{
"term": {
"channel_id.keyword": {
"value": "UCoztvTULBYd3WmStqYeoHcA"
}
}
}
]
}
},
"sort": [
{
"amount_micros": {
"order": "desc"
}
}
]
}
可以使用,來一直查詢多個索引,或是使用*
試用Aggregation API和kibana圖表
接著試著呼叫Aggregation API來取得一些資訊:
※資料因為許多原因,一定會有誤差(ex:API使用達上限、服務中斷、影片設定未公開…等等)
- 2020年11月共有多少支影片
GET /n7i-chats-202011/_search
{
"size":0,
"aggs": {
"videos": {
"cardinality": {
"field": "video_id.keyword"
}
}
}
}
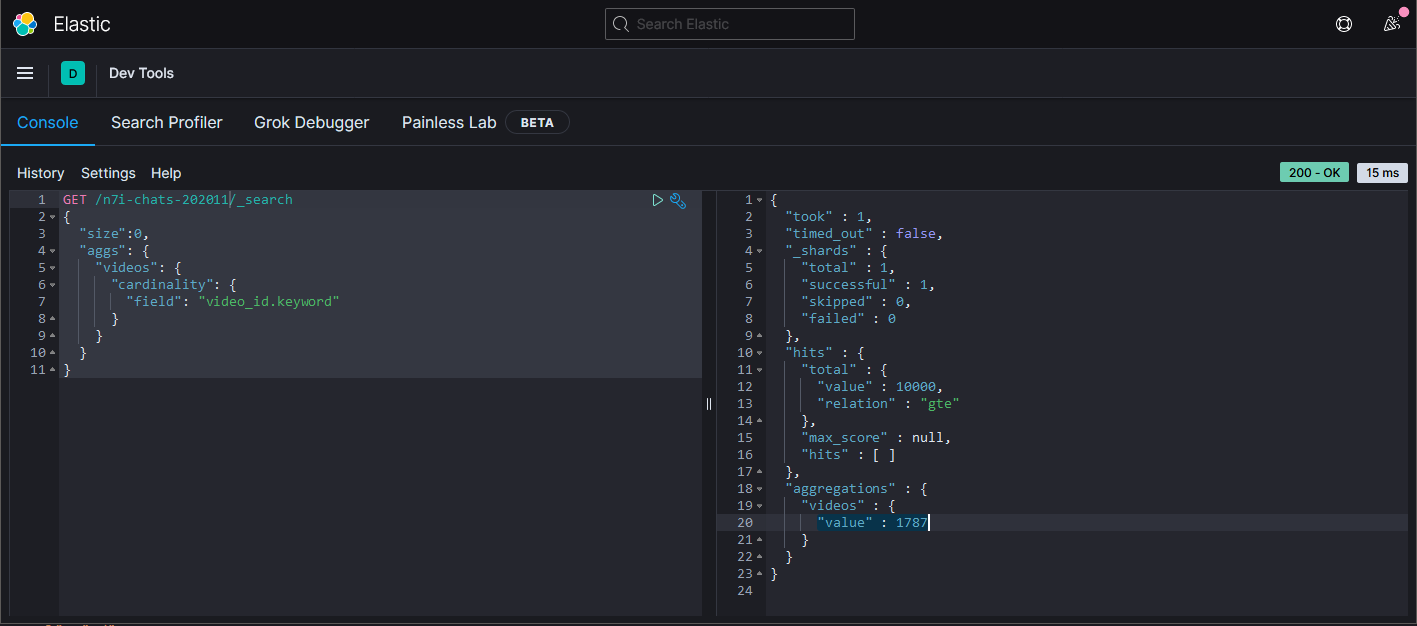
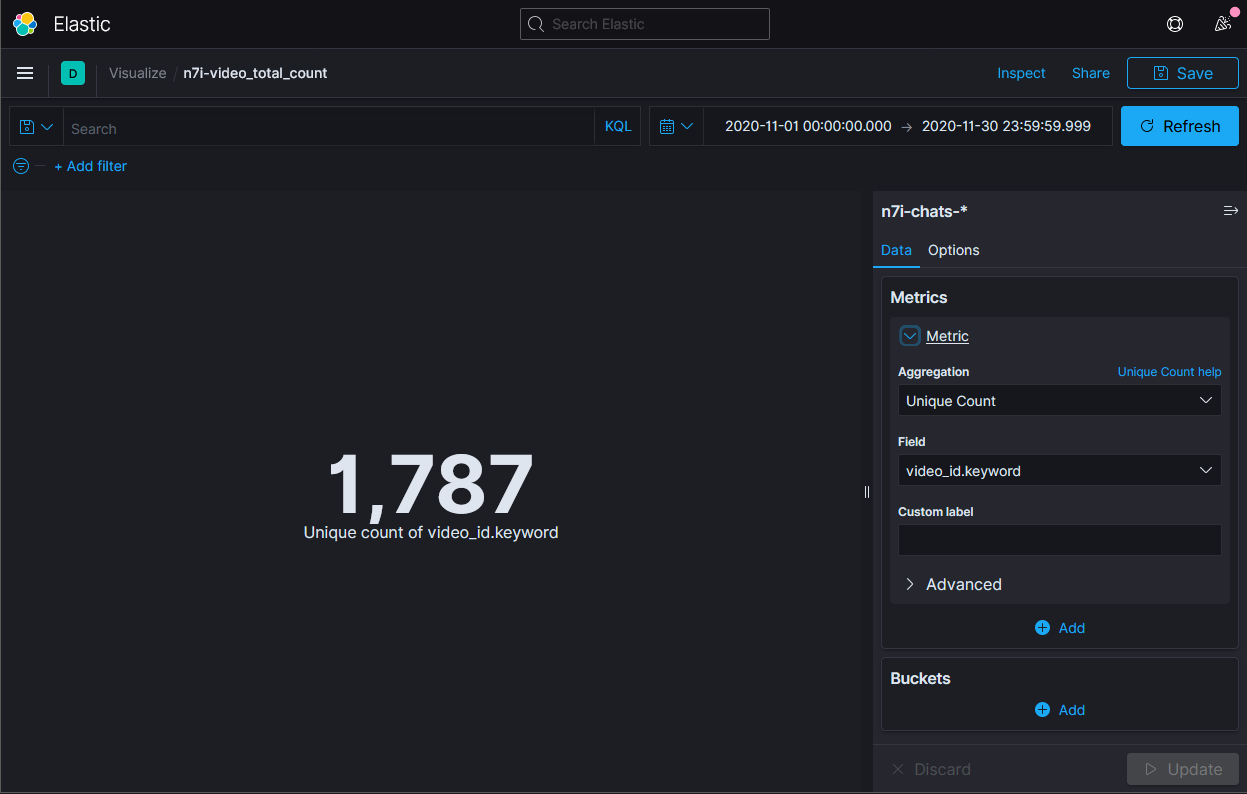
查詢結果是1787支影片。
- 2020年11月哪天直播最多
GET /n7i-chats-202011/_search
{
"size":0,
"aggs": {
"on_day": {
"date_histogram": {
"field": "post_time",
"calendar_interval": "1d",
"time_zone": "Asia/Taipei"
},
"aggs": {
"video": {
"cardinality": {
"field": "video_id.keyword"
}
},
"list": {
"terms": {
"field": "video_id.keyword",
"size": 80
}
},
"bs": {
"bucket_sort": {
"sort": [
{
"video": {
"order": "desc"
}
}
]
}
}
}
}
}
}
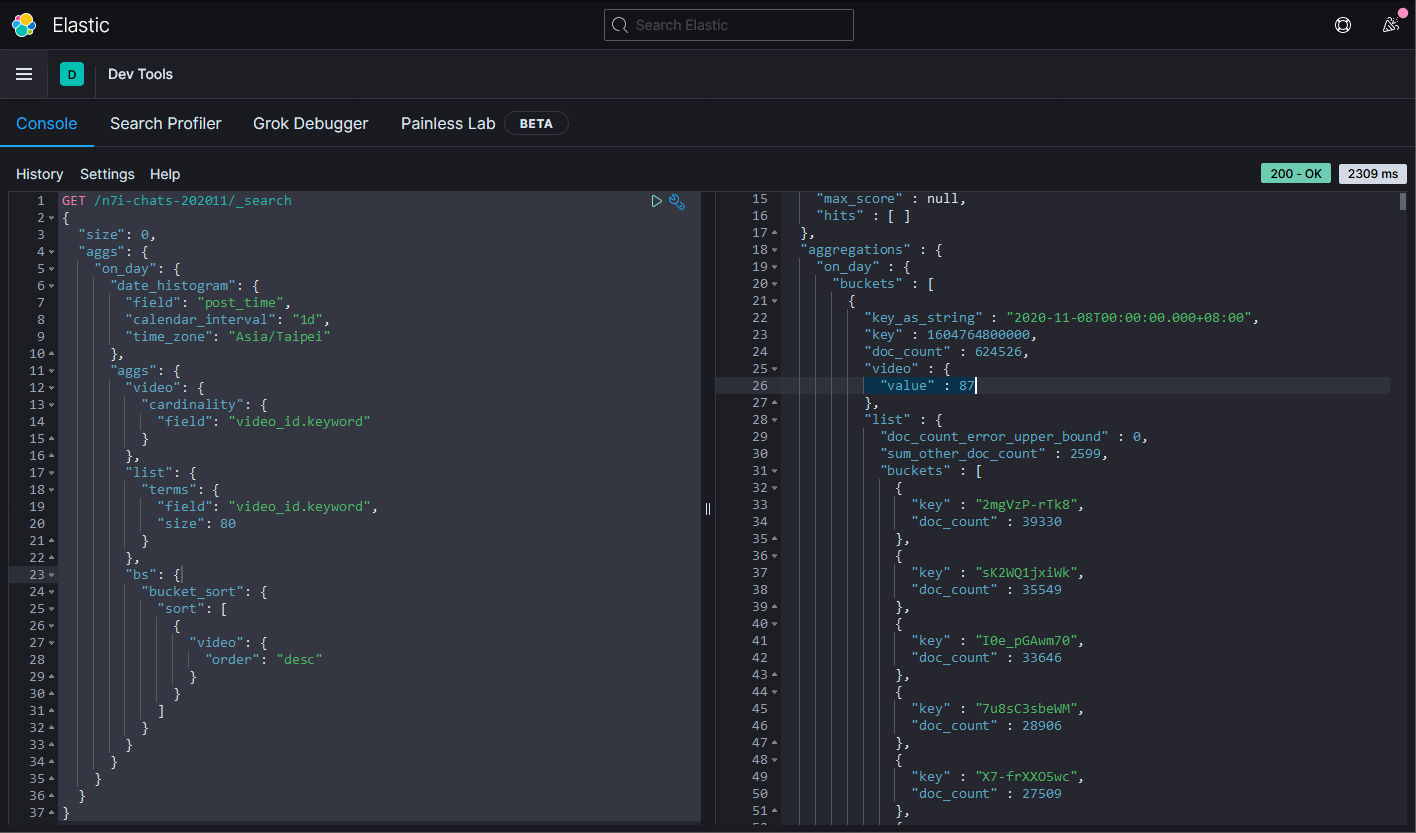
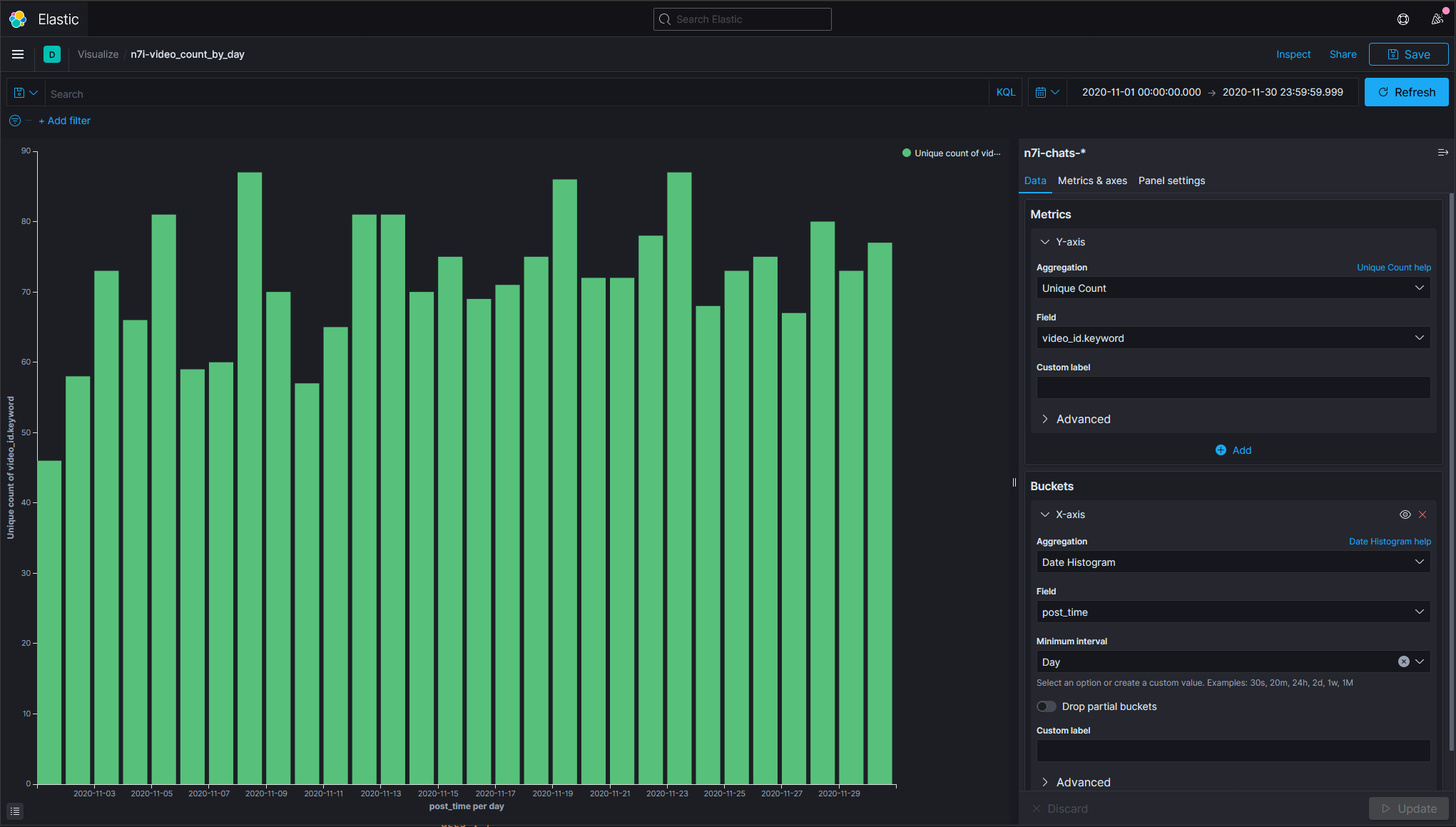
1108和1123這兩天的影片數有87支。最少的也有46支。
因為是拿聊天訊息的發送時間來計算,所以會有誤差(跨日的問題)。像是2020-11-07 22:16:11開始,直播時間有04:53:15的這類情況。
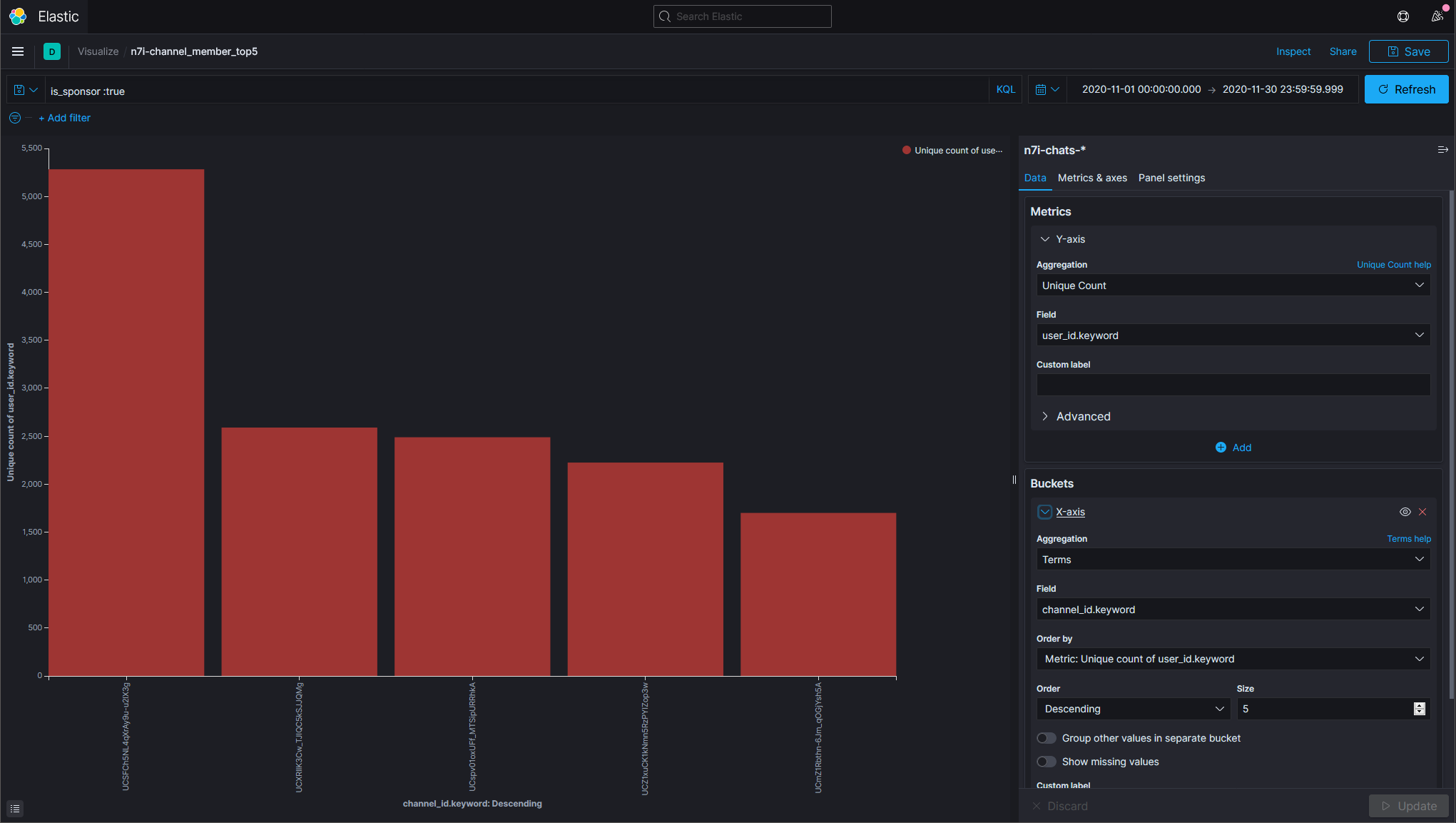
- 計算2020年11月每個頻道的影片數,並且以影片數來排序:由高至低
GET /n7i-chats-202011/_search
{
"size": 0,
"aggs": {
"channel": {
"terms": {
"field": "channel_id.keyword",
"size": 2147483647
},
"aggs": {
"videos": {
"cardinality": {
"field": "video_id.keyword"
}
},
"bs": {
"bucket_sort": {
"sort": [
{
"videos": {
"order": "desc"
}
}
]
}
}
}
}
}
}
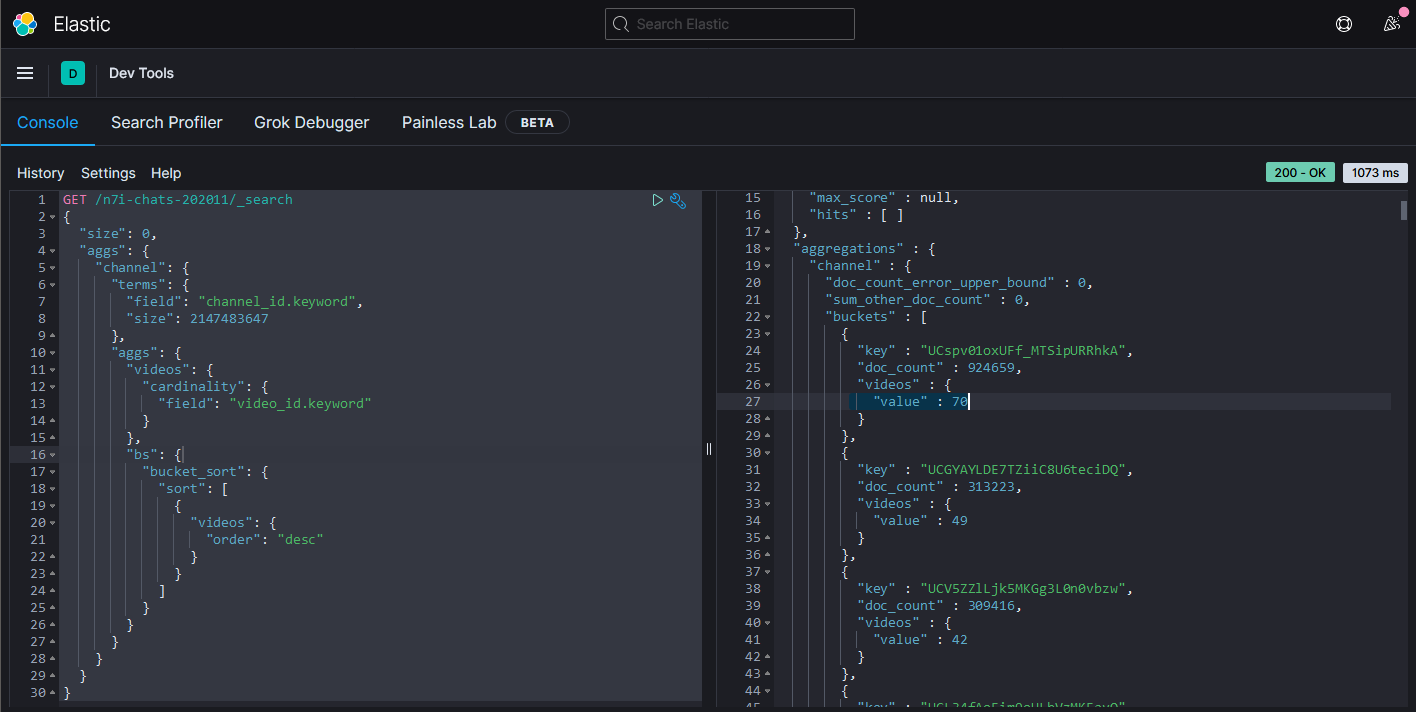
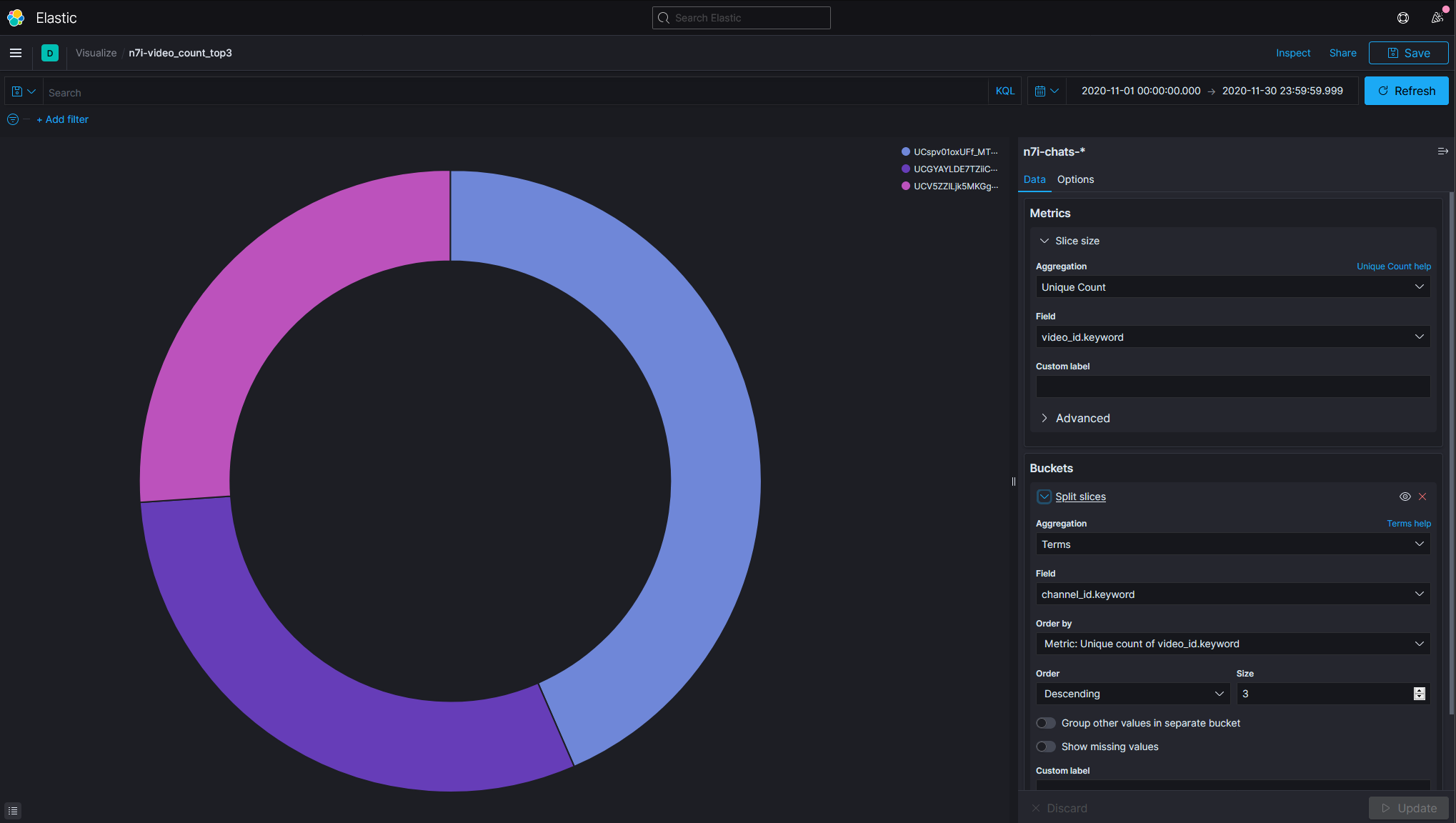
為了省一點檔案大小而沒有把頻道名稱存進去而只有存ID這時候就有點麻煩。
第一位是叶,共70支影片,有每次都是他的感覺。
第二位是葉加瀬冬雪,隻狼的影響吧。
第三位則是鷹宮リオン。
doc_count在這邊就是聊天訊息的數量。如果沒有特地加上bucket_sort的話,預設就是拿doc_count來排序。
- 顯示2020年11月各影片留言數,並且以留言數排序:由高至低、取前五支
GET /n7i-chats-202011/_search
{
"size": 0,
"aggs": {
"video" : {
"terms": {
"field": "video_id.keyword",
"size": 5
}
}
}
}

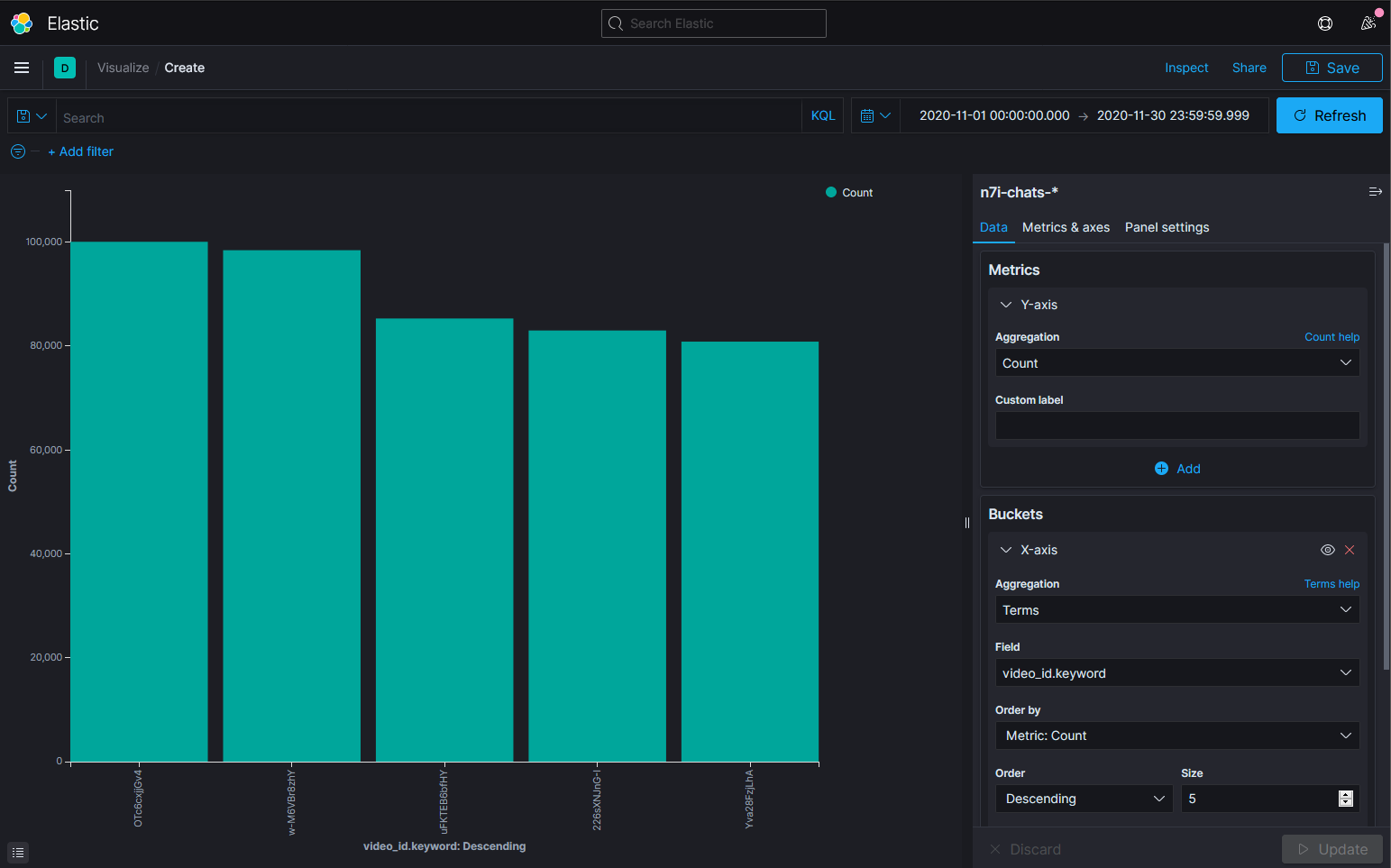
第一名是ドキ文 DDLC | ______。【にじさんじ/叶】 - YouTube。
- 顯示各個頻道在2020年11月有多少「人」有發過訊息,並且以人數排序:由高至低
GET /n7i-chats-202011/_search
{
"size": 0,
"aggs": {
"channel": {
"terms": {
"field": "channel_id.keyword",
"size": 2147483647
},
"aggs": {
"user": {
"cardinality": {
"field": "user_id.keyword"
}
},
"bs": {
"bucket_sort": {
"sort": [
{
"user": {
"order": "desc"
}
}
]
}
}
}
}
}
}
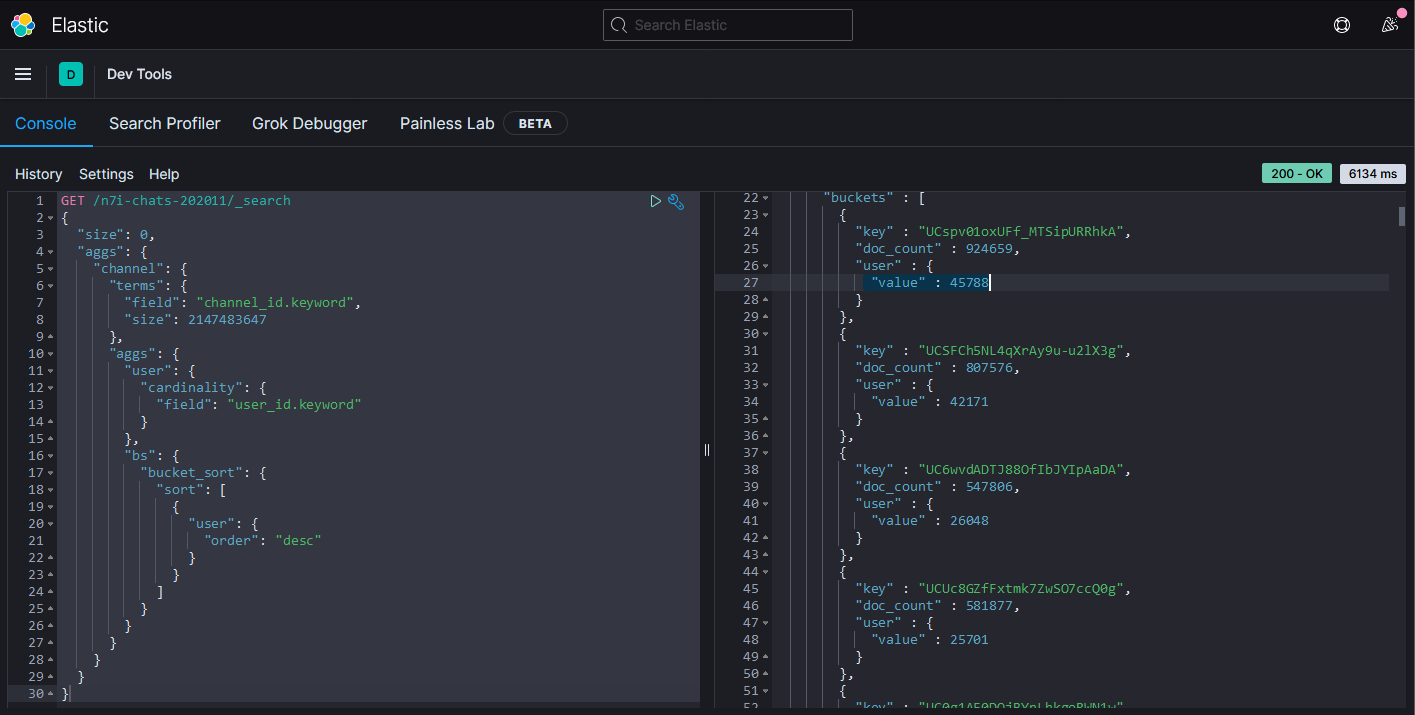

第一位是叶,共45788位。
第二名是葛葉。
第三名則是不破湊。
- 顯示各個頻道在2020年11月有多少「會員」發過訊息,並且以人數排序:由高至低
GET /n7i-chats-202011/_search?q=is_sponsor:true
{
"size": 0,
"aggs": {
"channel": {
"terms": {
"field": "channel_id.keyword",
"size": 2147483647
},
"aggs": {
"member": {
"cardinality": {
"field": "user_id.keyword"
}
},
"bs": {
"bucket_sort": {
"sort": [
{
"member": {
"order": "desc"
}
}
]
}
}
}
}
}
}
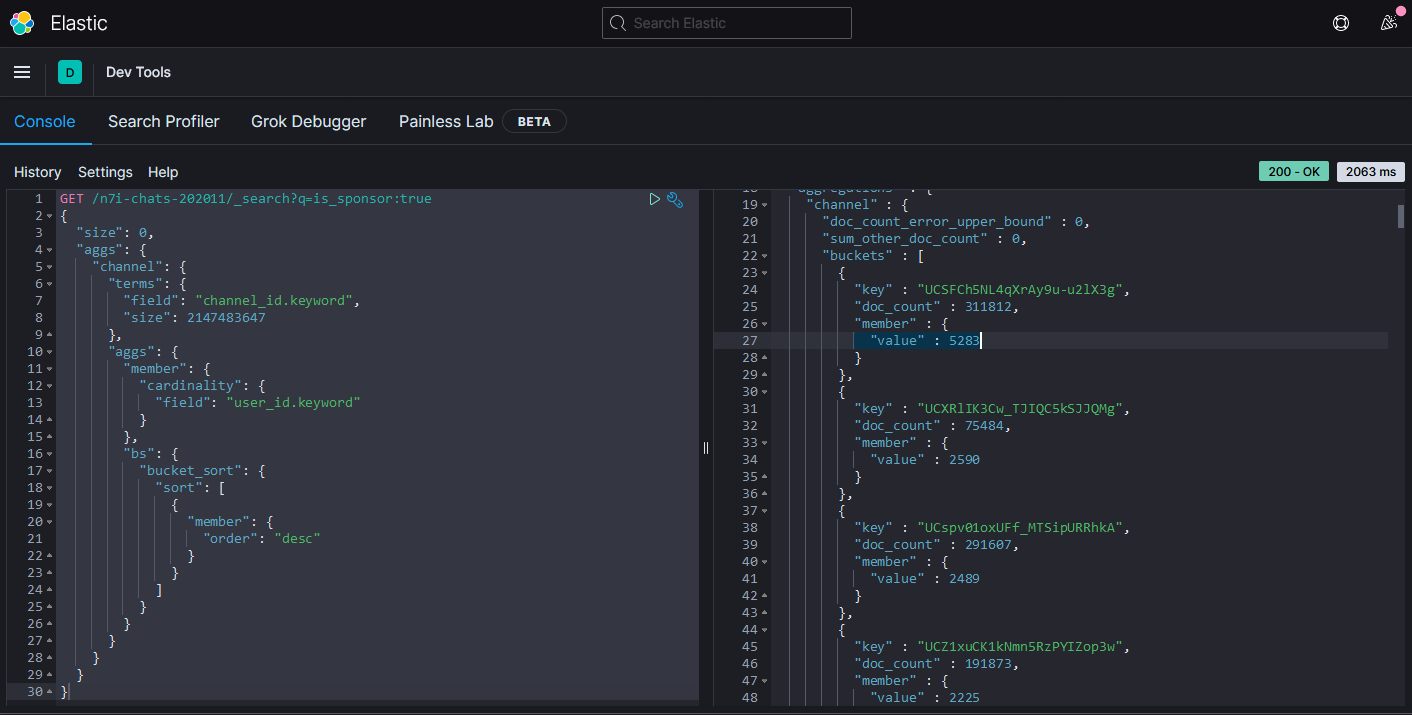
第一名是葛葉,共有5283位。
第二名是戌亥とこ。
第三名是叶。
- 顯示各Liver在2020年11月的發言數
GET /n7i-chats-202011/_search
{
"size":0,
"query": {
"bool": {
"filter": [
{
"terms": {
"user_id.keyword": [
"所有liver channel id"
...
]
}
}
]
}
},
"aggs": {
"liver_from": {
"terms": {
"field": "user_name.keyword",
"size": 200
},
"aggs": {
"live_to":{
"terms": {
"field": "channel_id.keyword",
"size": 200
}
}
}
}
}
}
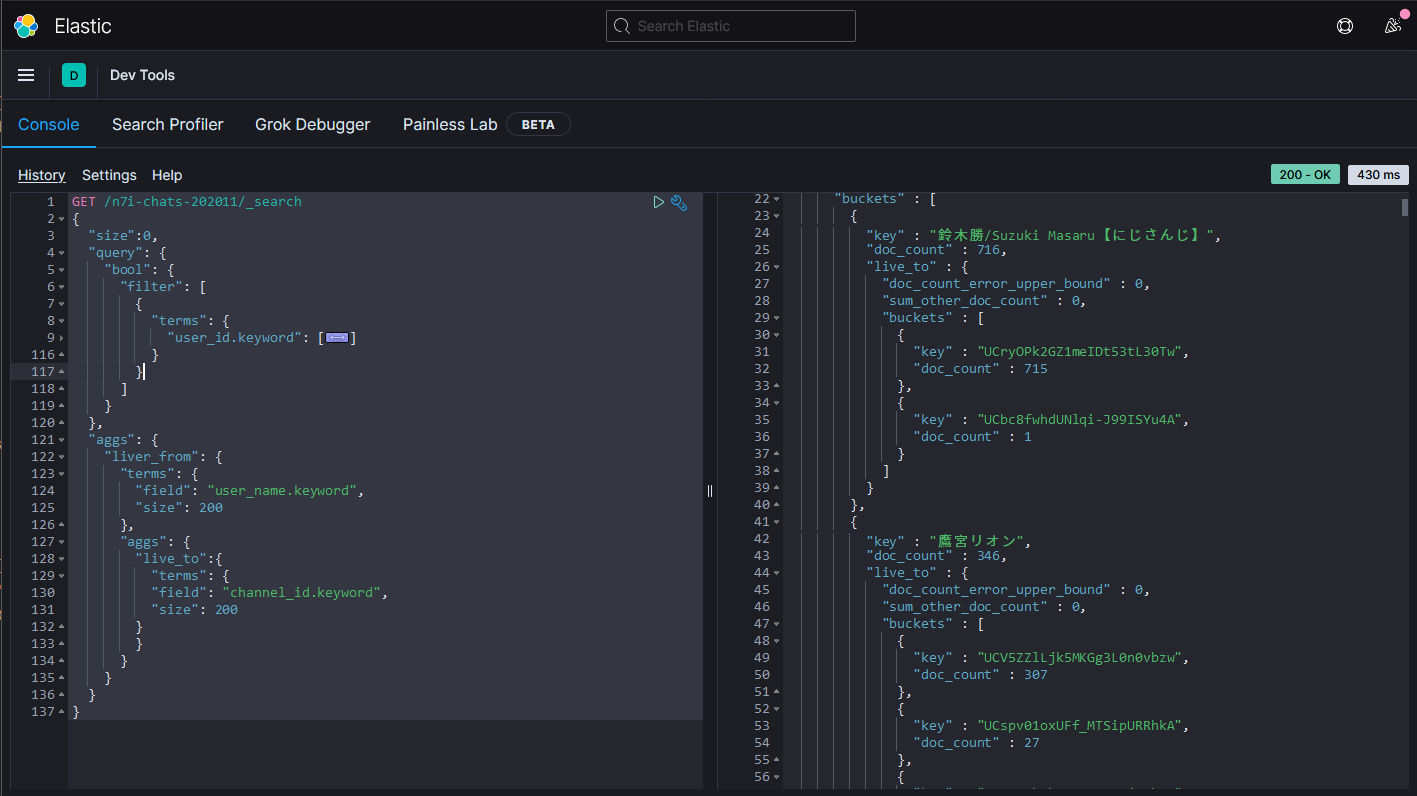
所有人總計在YouTube裡的留言數共有2333則。
第一名為鈴木勝,高達716則。
第二名為鷹宮リオン。
第三名為郡道美玲。
這部分因為格式的關係就不好產生圖表,因為沒有一個欄位可以篩選,用查詢的得打一百多個ID上去…
- 顯示各個頻道在2020年11月有多少新會員,並且以人數排序:由高至低
GET /n7i-chats-202011/_search?q=is_new_sponsor:true
{
"size": 0,
"aggs": {
"channel": {
"terms": {
"field": "channel_id.keyword",
"size": 2147483647
},
"aggs": {
"member": {
"cardinality": {
"field": "user_id.keyword"
}
},
"bs": {
"bucket_sort": {
"sort": [
{
"member": {
"order": "desc"
}
}
]
}
}
}
}
}
}
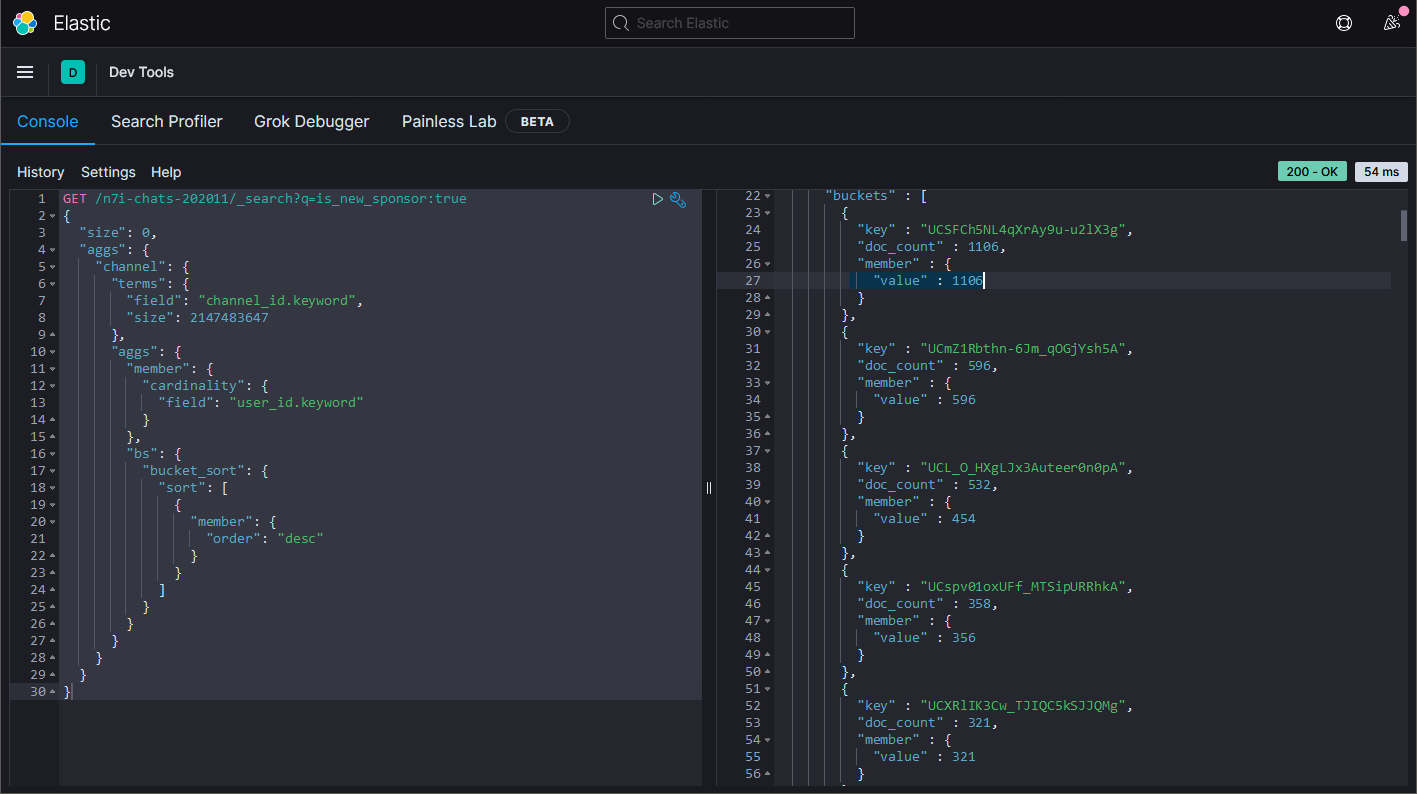
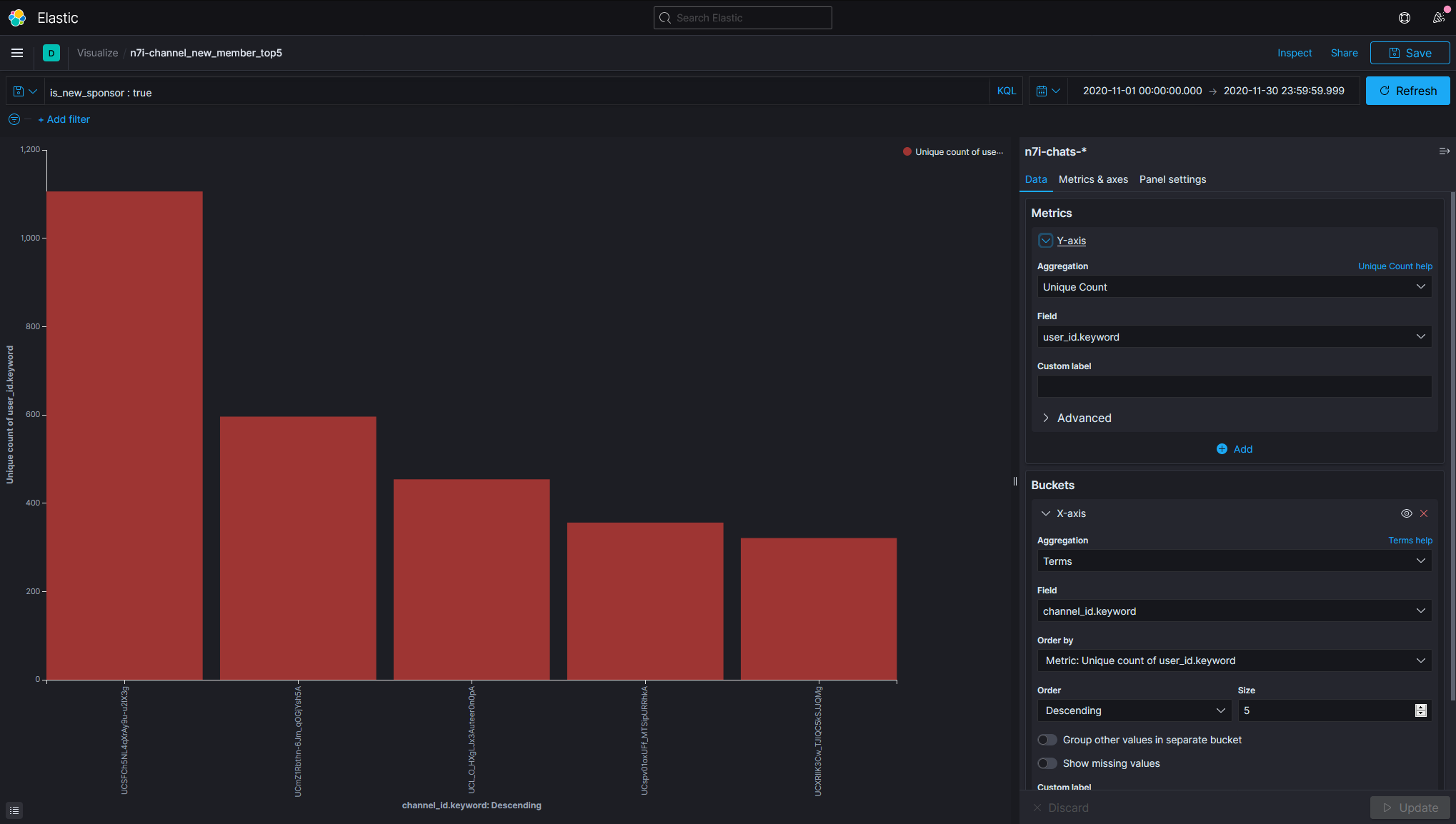
第一名是葛葉,共有1106位。
第二名是イブラヒム。
第三名是周央サンゴ。
- 顯示各個頻道在2020年有多少SuperChat,並且以總額排序:由高至低;並且列出前五名的帳號
GET /n7i-chats-202011/_search?size=0
{
"query": {
"range": {
"amount_micros": {
"gt": 0
}
}
},
"aggs": {
"channel": {
"terms": {
"field": "channel_id.keyword",
"size": 2147483647
},
"aggs": {
"sc": {
"sum": {
"field": "amount_micros"
}
},"user":{
"terms": {
"field": "user_id.keyword",
"size": 5
},"aggs":{
"total":{
"sum": {
"field": "amount_micros"
}
}
}
},
"bs": {
"bucket_sort": {
"sort": [
{
"sc": {
"order": "desc"
}
}
]
}
}
}
}
}
}
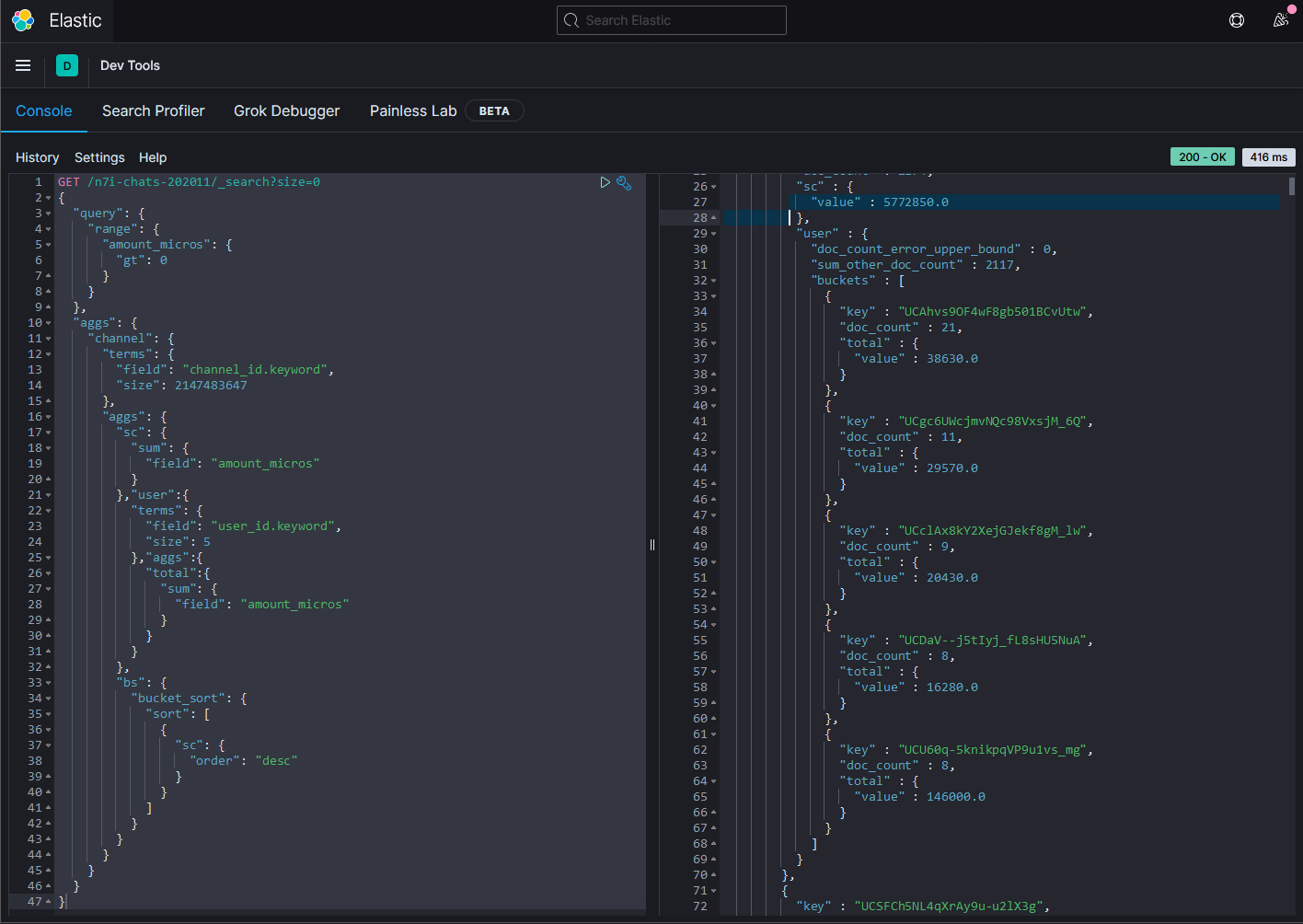
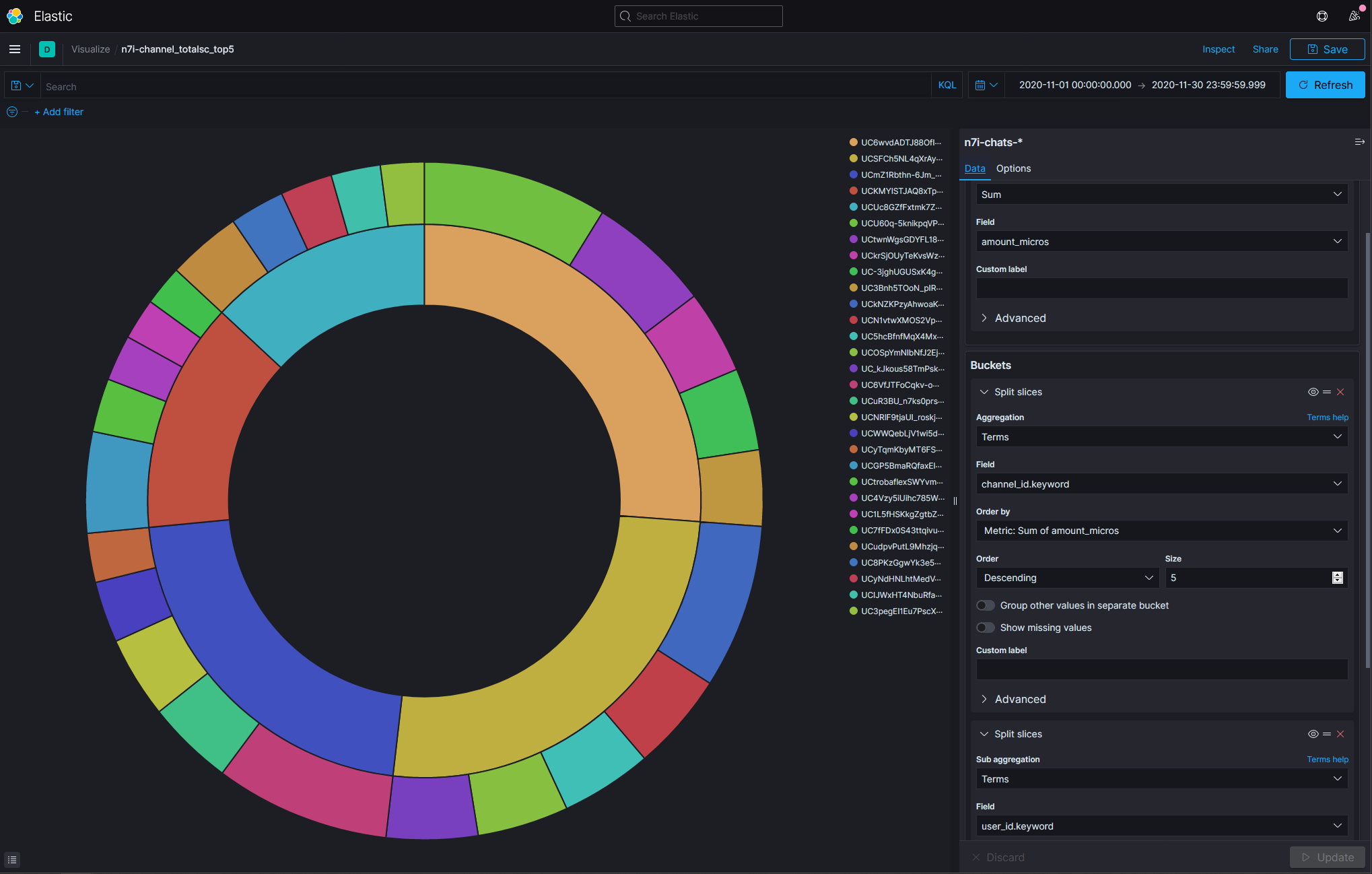
第一名是不破湊,有¥5772850。
第二名是葛葉。
第三名是イブラヒム。
很意外的前三不是女性。
圖表中的內圈是channel_id,外圈則是user_id。
- 顯示2020年11月前五名發言數的帳號並列出發言數前五高的頻道
GET /n7i-chats-202011/_search
{
"size": 0,
"aggs": {
"user": {
"terms": {
"field": "user_id.keyword",
"size": 5,
"order": {
"_count": "desc"
}
},
"aggs": {
"channel": {
"cardinality": {
"field": "channel_id.keyword"
}
},
"list": {
"terms": {
"field": "channel_id.keyword",
"size": 5
}
}
}
}
}
}
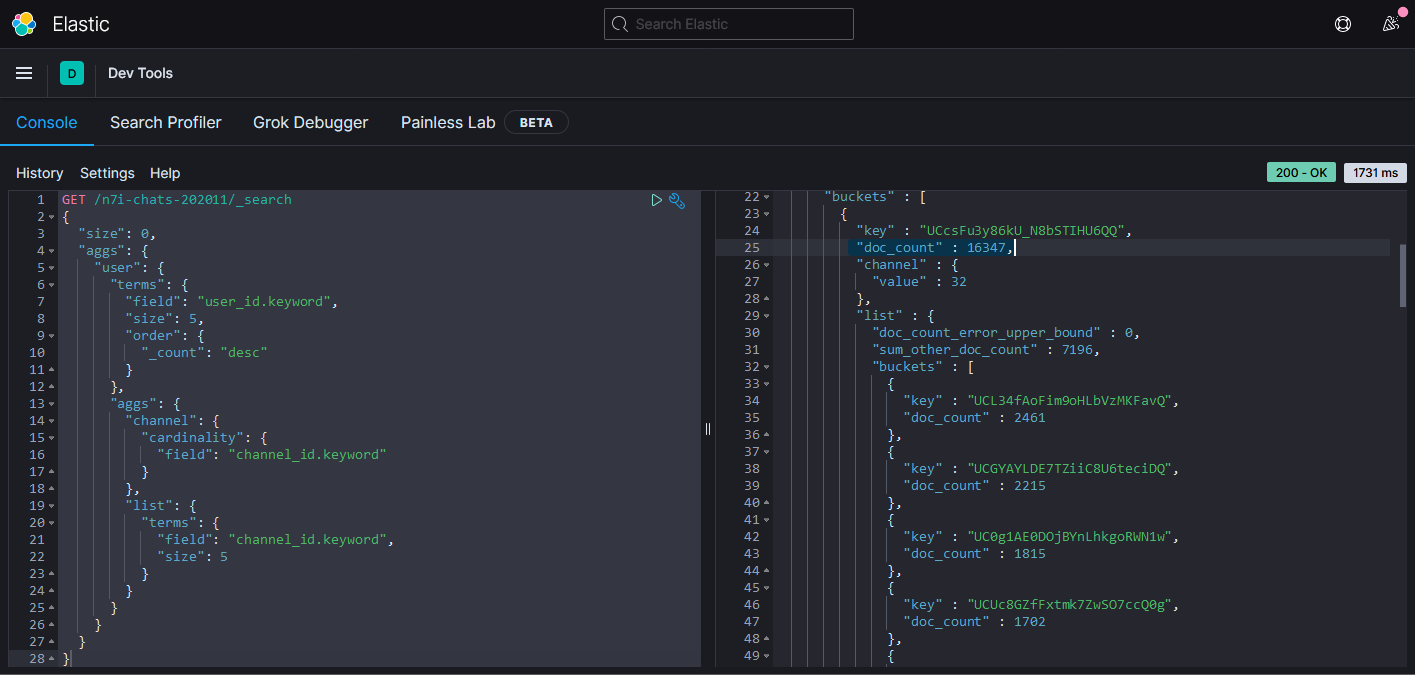
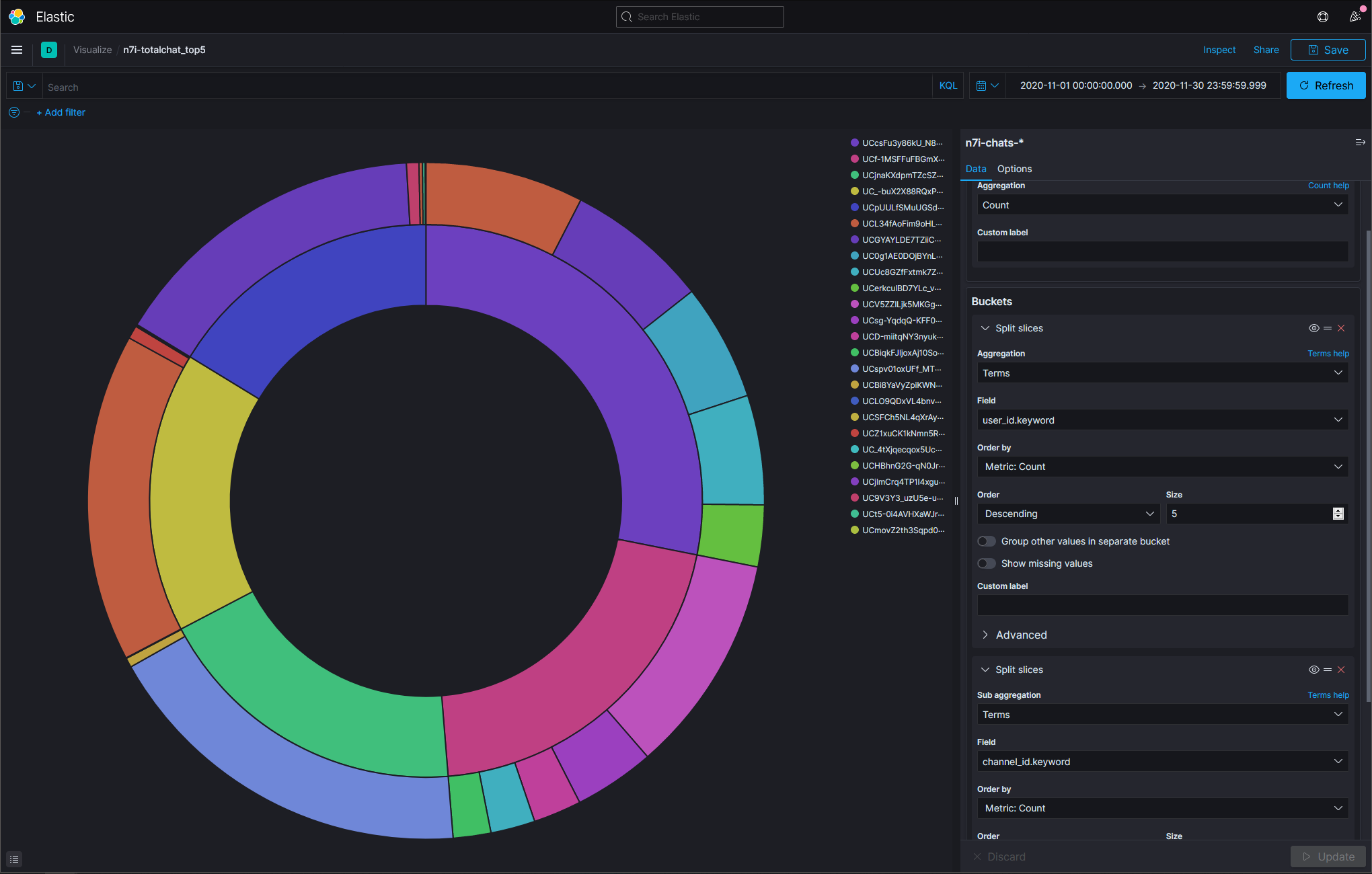
第一名有16347則訊息,分散在32個頻道,大多在夜見れな,接著是葉加瀬冬雪。
圖表可以看出有兩位的守備範圍(?)蠻廣的,後三位則是接近單推(?)的感覺。
其實還不太清楚怎麼驗證,不能肯定user下的size:5就真的是取前五名。目前是加大size和min_doc_count的數字後觀察bucket的前幾項的順序沒有變化才判斷他應該是真的取前五名。
- 顯示2020年11月前五名SC金額的帳號
GET /n7i-chats-202011/_search?size=0
{
"query": {
"range": {
"amount_micros": {
"gt": 0
}
}
},
"aggs": {
"user": {
"terms": {
"field": "user_id.keyword",
"size": 5,
"order": {
"total_sc": "desc"
}
},
"aggs": {
"total_sc": {
"sum": {
"field": "amount_micros"
}
},
"to_channel": {
"terms": {
"field": "channel_id.keyword",
"size": 5
},
"aggs": {
"total": {
"sum": {
"field": "amount_micros"
}
}
}
},
"bs": {
"bucket_sort": {
"sort": [
{
"total_sc": {
"order": "desc"
}
}
]
}
}
}
}
}
}
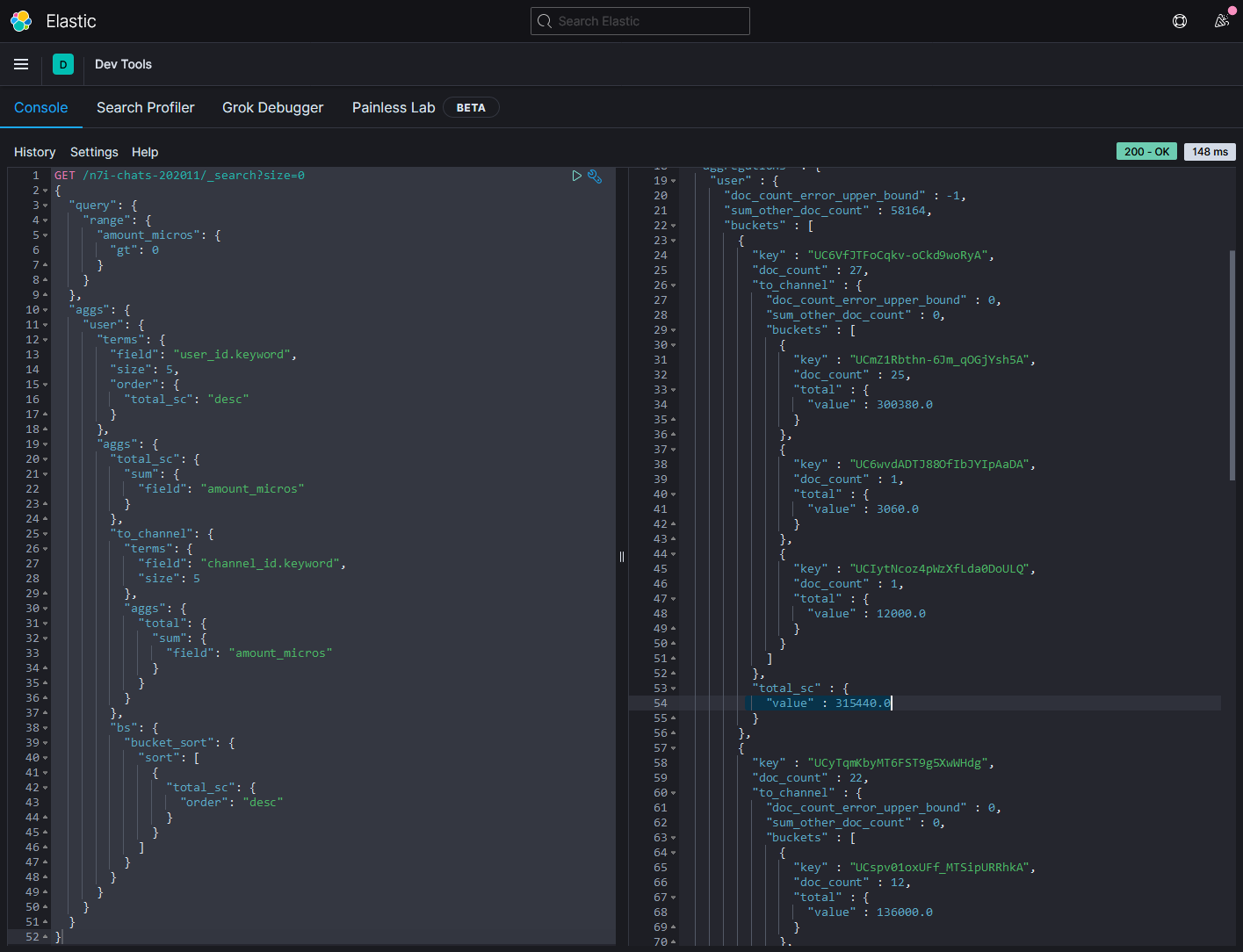
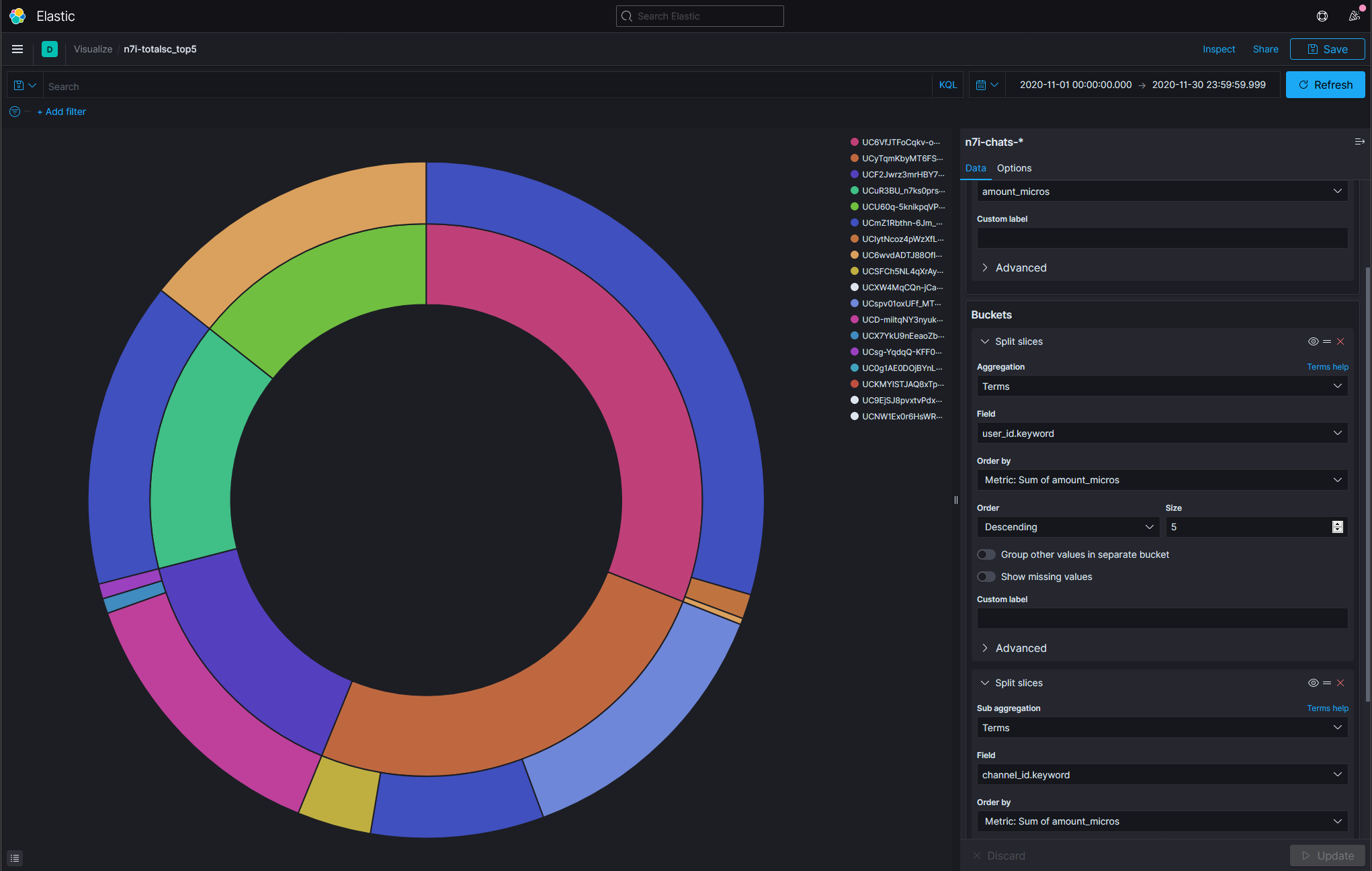
第一名共SC了27次,共¥315440,大多是給イブラヒム。
- 列出2020年11月各頻道的關鍵字出現次數
GET /n7i-chats-202011/_search
{
"size": 0,
"query": {
"bool": {
"should": [
{
"match_phrase": {
"content": "天才"
}
},
{
"match_phrase": {
"content": "かしこい"
}
},
{
"match_phrase": {
"content": "助かる"
}
},
{
"match_phrase": {
"content": "たすかる"
}
},
{
"match_phrase": {
"content": "てぇてぇ"
}
},
{
"match_phrase": {
"content": "うまい"
}
},
{
"match_phrase": {
"content": "ナイス"
}
},
{
"match_phrase": {
"content": "いいね"
}
},
{
"match_phrase": {
"content": "上手い"
}
},
{
"match_phrase": {
"content": "フラグ"
}
},
{
"match_phrase": {
"content": "flag"
}
},
{
"match_phrase": {
"content": "おかえり"
}
},
{
"match_phrase": {
"content": "えらい"
}
},
{
"match_phrase": {
"content": "すき"
}
},
{
"match_phrase": {
"content": "スキ"
}
},
{
"match_phrase": {
"content": "好き"
}
},
{
"match_phrase": {
"content": "不仲"
}
},
{
"match_phrase": {
"content": "うんち"
}
},
{
"match_phrase": {
"content": "💩"
}
},
{
"match_phrase": {
"content": "炎上"
}
},
{
"match_phrase": {
"content": "🔥"
}
},
{
"match_phrase": {
"content": "不憫"
}
},
{
"match_phrase": {
"content": "カワイイ"
}
},
{
"match_phrase": {
"content": "かわいい"
}
}
],
"minimum_should_match": 1
}
},
"aggs": {
"count": {
"filters": {
"filters": {
"pity": {
"match_phrase": {
"content": "不憫"
}
},
"fire": {
"bool": {
"should": [
{
"match_phrase": {
"content": "炎上"
}
},
{
"match_phrase": {
"content": "🔥"
}
}
]
}
},
"poop": {
"bool": {
"should": [
{
"match_phrase": {
"content": "うんち"
}
},
{
"match_phrase": {
"content": "💩"
}
}
]
}
},
"discord": {
"match_phrase": {
"content": "不仲"
}
},
"likes": {
"bool": {
"should": [
{
"match_phrase": {
"conetnt": "すき"
}
},
{
"match_phrase": {
"conetnt": "スキ"
}
},
{
"match_phrase": {
"conetnt": "好き"
}
}
]
}
},
"great": {
"match_phrase": {
"content": "えらい"
}
},
"comeback": {
"match_phrase": {
"content": "おかえり"
}
},
"flag": {
"bool": {
"should": [
{
"match_phrase": {
"content": "フラグ"
}
},
{
"match_phrase": {
"content": "flag"
}
}
]
}
},
"nice": {
"bool": {
"should": [
{
"match_phrase": {
"content": "うまい"
}
},
{
"match_phrase": {
"content": "ナイス"
}
},
{
"match_phrase": {
"content": "ないす"
}
},
{
"match_phrase": {
"content": "いいね"
}
},
{
"match_phrase": {
"content": "上手い"
}
}
]
}
},
"tete": {
"match_phrase": {
"content": "てぇてぇ"
}
},
"genius": {
"bool": {
"should": [
{
"match_phrase": {
"content": "天才"
}
},
{
"match_phrase": {
"content": "かしこい"
}
}
]
}
},
"helpful": {
"bool": {
"should": [
{
"match_phrase": {
"content": "助かる"
}
},
{
"match_phrase": {
"content": "たすかる"
}
}
]
}
},
"cute": {
"bool": {
"should": [
{
"match_phrase": {
"content": "カワイイ"
}
},
{
"match_phrase": {
"content": "かわいい"
}
}
]
}
}
}
},
"aggs": {
"channel": {
"terms": {
"field": "channel_id.keyword",
"size": 200
}
}
}
}
}
}
同義詞應該是有方法可以處理,只不過現在還不熟所以只能用這種寫法。
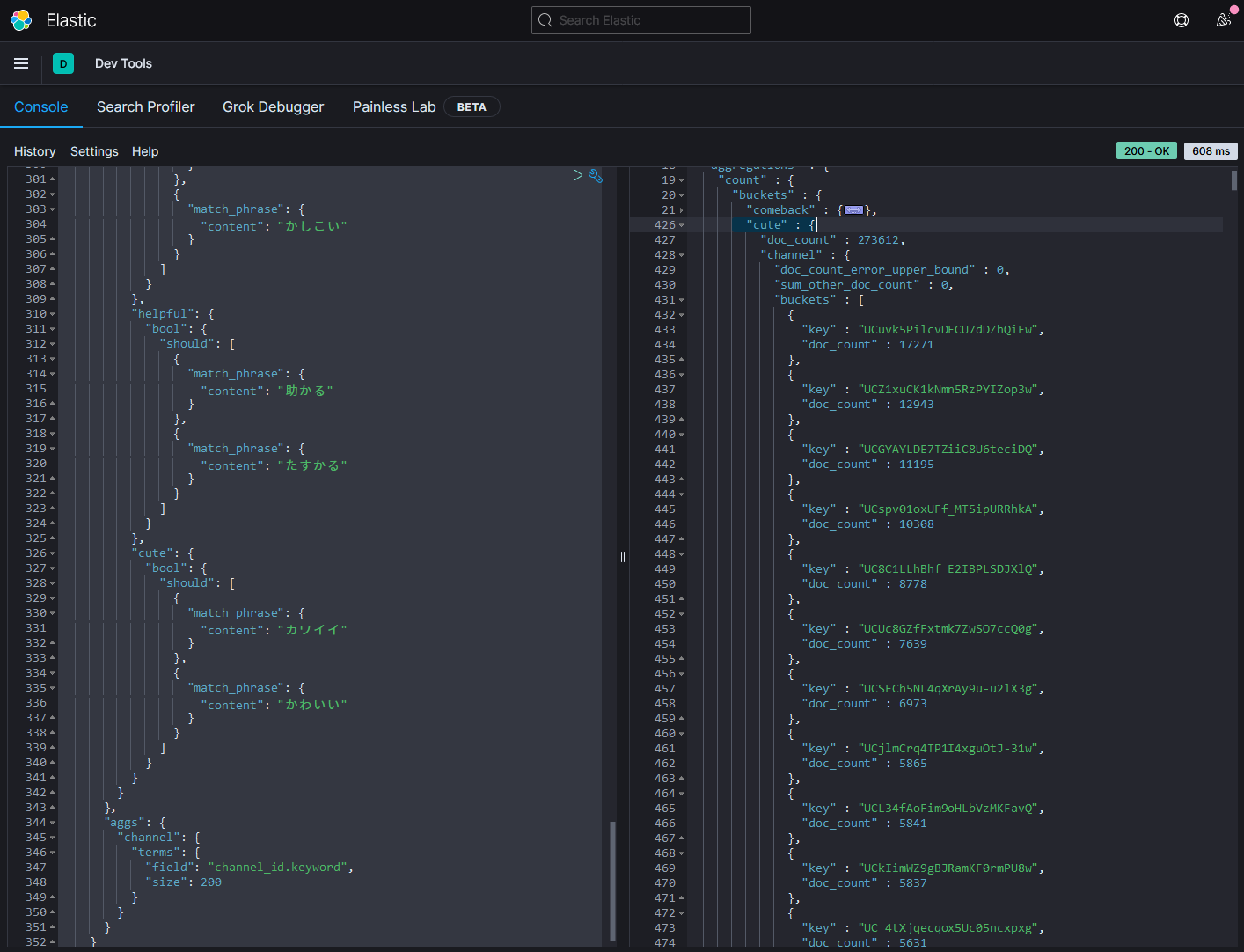
かわいい出現次數最多的是白雪巴。
炎上出現次數最多的是町田ちま。
たすかる出現次數最多的是叶。
最後把圖表整進一個dashboard裡面看看。
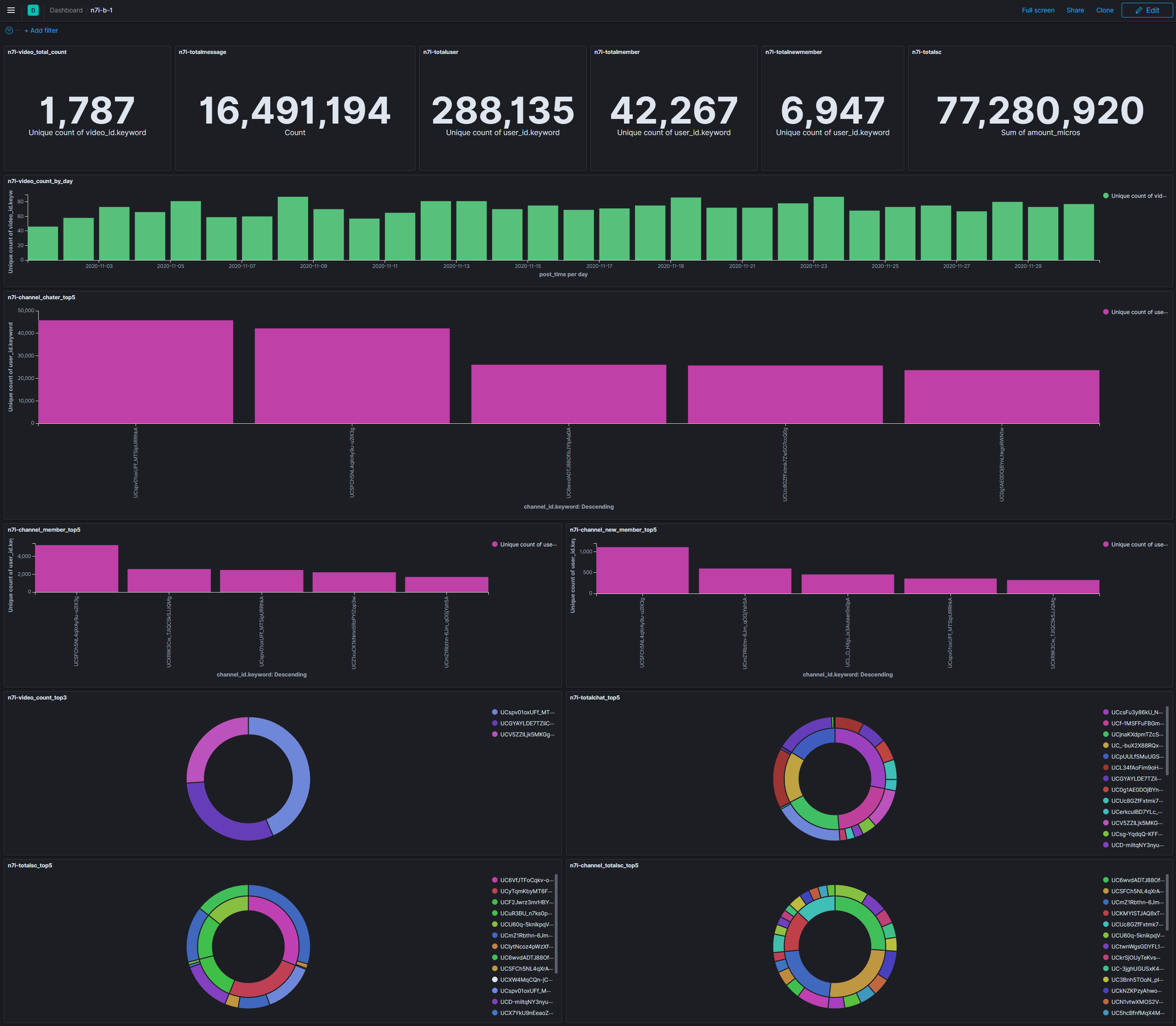
雖然圖表有點陽春,不過只是簡單按幾個選項就可以看到這些結果就已經很不錯了。
目前心得
elasticsearch aggregation的語法跟SQL語法差距很大,用JSON寫起來也會有很多個括號導致閱讀困難,像是我常常在插入sort語法的時候放錯位置,一直在那邊算括號。
但是只要在熟悉這些功能和語法後,有些地方寫起來應該還是比SQL省力的。
其實目前比較想做但沒有方向的部分就是對每個訊息內容斷詞然後統計出現次數,而不是像上面的關鍵字那樣需要自己定義。
目前自己是有使用node.js+Rakuten MA和kuromoji.js測試,但真的是太慢而且統計的部分得自己動手,想說elasticsearch應該有更快且簡單的方法…